fast-lio框架里面重要的推导和原理
slam框架
首先放slam结构图
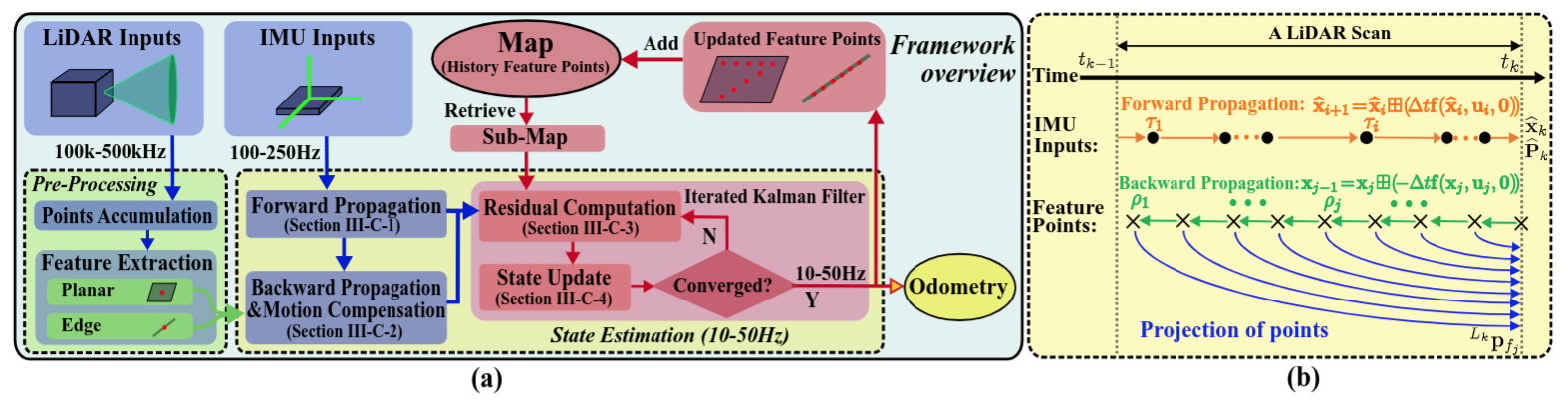
fast-lio可以说是一个很轻量的基于EKF的slam前端,他不包含slam的后端优化部分,采用迭代拓展卡尔曼滤波的方式输出雷达频率的后验位姿。并采用滑窗法(ikd-tree)保证局部子图。
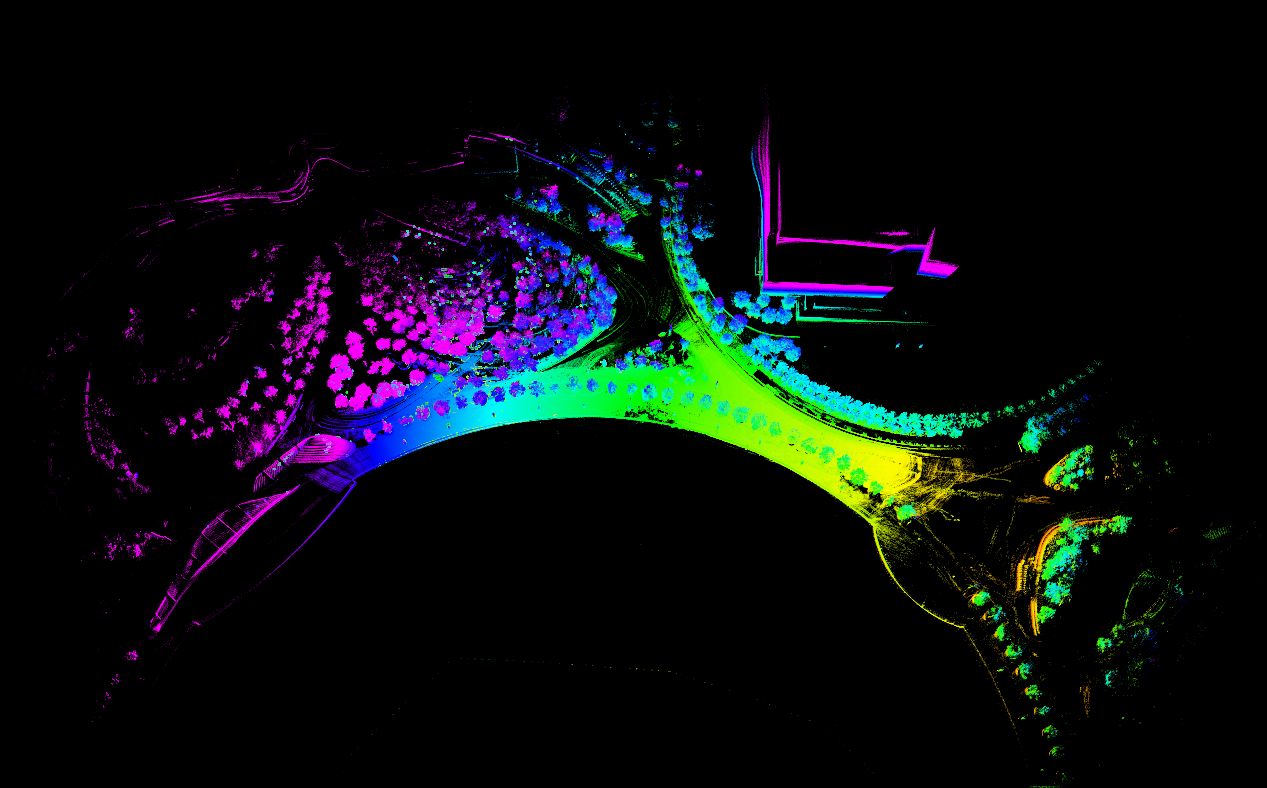
16线雷达数据集运行效果
预处理和前向传播
对于一帧雷达数据,在提取完角点和平面点特征之后。我们首先需要根据这帧雷达第一个点和最后一个点中间的imu数据计算这一帧结束后的先验状态和先验方差。
后向传播和残差计算
当得到这一帧雷达在$i+1$时刻的先验状态后,我们反向传播计算每一个雷达特征点时刻的状态,这些状态的频率远高于imu的频率。这样,就可以将每一个特征点状态的特征转换到$i+1$时刻坐标系下。
残差计算就是将$i+1$时刻的特征点和滑动的局部子图找最近点,然后计算点到面和点到线的残差。
迭代拓展误差状态卡尔曼滤波
这里就是本篇论文的一个核心点,计算卡尔曼增益的时候将观测状态维度的求拟转化到状态维度的求逆。
原始卡尔曼增益:
\[K = PH^T(HPH^T + R)^{-1}\]论文转化后卡尔曼增益:
\[K = (H^TR^{-1}H + P^{-1})H^TR^{-1}\]总结
fast-lio主要还是基于卡尔曼滤波那一套,论文中说在非结构话的环境中依然能有效建图,并且建图的墙面没有出现变厚的情况。因此可以认为本质上还是更相信imu的状态预测的,当环境出现退化或者特征点无法匹配的情况,那观测的方差就会变大,更相信预测的值。
和lio-sam对比,根据实验室师兄的测试,fast-lio在楼梯场景下不会出现退化,但是lio-sam会出现漂移。单纯的slam的rmse评估,也是fast-lio更加准确。
lio-sam的优势在于使用了因子图优化的思想,并且加上了回环检测部分,所以在面对大场景的时候应该会有更好的效果,并且也支持GPS传感器,拓展性和可读性也更好。